


介绍
这篇文章的目的是在ESP32上实现一个简单的功率计算算法,并通过在微控制器的两个内核中执行它来测试加速。
正如我们在之前的教程中所述,ESP32有两个Tensilica LX6内核[1],我们可以使用它来执行代码。在写这篇文章的时候,在ESP32控制代码的不同内核执行的最简单的方法是使用FreeRTOS操作系统和任务分配给每个CPU,如能详细地看到这个以前的帖子。
虽然通用方式有多个核心可用于执行代码,但其中一个最重要的是提高程序的性能。因此,虽然我们已经看到了如何在ESP32的两个核心中执行代码,但我们还没有看到我们可以从中获得的性能提升。
因此,在本教程中,我们将设计一个能够计算数组数量的简单应用程序。我们将在单核中运行它,然后我们将通过两个核拆分处理并检查执行时间是否有增益。最后,为了进行比较,我们还将在四个任务(两个分配给每个核心)之间分割执行,以检查是否有任何加速来产生比核心更多的任务。
计算加速
我们想要检查的是当我们从单核心执行转移到双核执行时,我们程序的执行速度会增加多少。因此,最简单的方法之一是通过在仅一个核心上运行的程序的执行时间与在ESP32的两个核心上运行之间的比率来实现。
我们将使用Arduino micros函数测量每种方法的执行时间,该函数返回自电路板开始运行程序以来的微秒数。
因此,为了测量执行代码块,我们将执行类似于下面指出的操作:
start = micros();
//Run code
end = micros();
execTime = end - start;
我们可以使用FreeRTOS xTaskGetTickCount 函数来获得更高的精度,但微函数对于我们想要显示的内容来说已经足够了,它是一个众所周知的Arduino函数。
全局变量
我们将通过声明一些辅助全局变量来启动我们的代码。
由于我们将在不同情况下比较加速,我们将指定一个具有多个指数的数组来尝试。此外,我们将有一个具有数组大小的变量,因此我们可以迭代它。我们首先要为指数尝试小值,然后开始增加它们。
int n [10] = {2,3,4,5,10,50,100,1000,2000,10000};
int nArraySize = 10;
我们还将有一些变量来存储代码在不同用例中的执行时间。我们将重用执行 开始和结束 变量,但为每个用例使用不同的变量:一个任务执行,两个任务执行和四个任务执行。这样,我们将存储后一个比较的值。
unsigned long start;
unsigned long end;
unsigned long execTimeOneTask, execTimeTwoTask, execTimeFourTask ;
然后,我们将声明一个计数信号量,以便能够将设置功能(在FreeRTOS任务上运行)与我们要启动的任务同步。有关如何实现此类同步的详细说明,请参阅此文章。
请注意,xSemaphoreCreateCounting函数接收信号量的最大计数和初始计数作为输入。由于我们最多将有4个任务同步,因此其最大值将为4。
SemaphoreHandle_t barrierSemaphore = xSemaphoreCreateCounting( 4, 0 );
最后,我们将声明两个数组:一个具有初始值(称为bigArray),另一个用于存储结果(称为resultArray)。我们会把他们的尺寸做大。
int bigArray[10000], resultArray[10000];
FreeRTOS任务
我们将定义将实现我们的功率计算算法的功能,以便作为任务启动。如果您需要帮助有关如何定义FreeRTOS的任务的具体情况,请检查此之前的教程。
我们需要考虑的第一件事是我们的函数将接收一些配置参数。由于在某些用例中我们将通过各种任务分割算法的执行,我们需要控制每个任务将覆盖的数组部分。
为了只创建可以回答所有用例的通用任务,我们将传递任务将作为参数负责的数组的索引。此外,我们将传递指数,因此我们现在需要执行多少次乘法。您可以更详细地检查了如何将参数传递到FreeRTOS的任务,在此之前的教程。
因此,我们将首先使用这3个参数定义一个结构,因此我们可以将它传递给我们的函数。您可以在此处阅读有关结构的更多信息。请注意,此结构在任何函数之外声明。因此,代码可以放在全局变量声明附近。
struct argsStruct {
int arrayStart;
int arrayEnd;
int n;
};
因为我们已经声明了我们的结构,所以在函数内部我们将声明一个这种结构类型的变量。然后,我们将函数的输入参数分配给此变量。请记住,参数作为指向null(void *)的指针传递给FreeRTOS函数,我们有责任将其强制转换回原始类型。
还要注意,我们向函数传递一个指向原始变量而不是实际变量的指针,因此我们需要使用指针来访问该值。同样,请参阅上一篇文章,了解有关此过程的详细说明。
argsStruct myArgs = *((argsStruct*)parameters);
现在,我们将实现功率计算功能。请注意,我们可以使用Arduino pow函数,但我会解释为什么我们没有。因此,我们将使用循环实现该函数,其中我们将值自身乘以n次。
我们首先声明一个变量来保存部分产品。然后,我们将执行for循环来迭代分配给任务的数组的所有元素。请记住,这是我们最初的目标。然后,对于每个元素,我们将计算其功效,最后我们将值分配给结果数组。这确保了我们将在所有测试中使用相同的数据,并且我们不会更改原始数组。
为了更清晰的代码,我们可以在专用函数中实现pow算法,但我想最小化辅助函数调用以获得更紧凑的代码。
检查下面的代码。我离开那里评论了一行代码,用pow函数计算功率,所以如果你愿意,你可以尝试一下。请注意,加速结果将有很大不同。此外,为了访问struct变量的元素,我们使用变量点(“。”)的名称作为元素的名称。
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}
检查下面的完整功能代码。请注意,代码的结尾我们将全局计数信号量增加一个单位。这样做是为了确保与设置功能同步,因为我们将从那里计算执行时间。查看该如何任务,FreeRTOS的信号灯同步以前的帖子。此外,最后,我们将删除该任务:
void powerTask( void * parameters ) {
argsStruct myArgs = *((argsStruct*)parameters);
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}
xSemaphoreGive(barrierSemaphore);
vTaskDelete(NULL);
}
设置功能
我们将在setup函数中执行所有剩余的代码,因此我们的主循环将为空。我们将从打开串行连接开始,输出测试结果。
Serial.begin(115200); Serial.println();
现在,我们将使用一些值初始化数组以应用计算。请注意,我们不关心数组的内容,也不关心实际结果,而是关注执行时间。因此,我们将使用随机值初始化数组只是为了显示这些函数,因为我们不会打印将保存结果的数组。
我们首先要调用randomSeed函数,因此生成的随机值在程序的不同执行中会有所不同[4]。如所指出的在这里,如果模拟引脚未被连接,它会返回对应于随机噪声,这是理想的传递作为输入值randomSeed功能。
之后,我们可以简单地调用random 函数,将可返回的最小值和最大值作为参数传递[4]。同样,我们这样做只是为了说明目的,因为我们不打算打印数组的内容。
randomSeed(analogRead(0));
for (int i = 0; i < 10000; i++) {
bigArray[i] = random(1, 10);
}
现在,我们将定义将用作任务参数的变量。记住先前声明的结构,它将保存每个任务将处理的数组的索引和指数。
因此,结构的第一个元素是起始索引,第二个是最终索引,第三个是指数。我们将为每个用例声明结构(一个任务,两个任务和四个任务),如下面的代码所示。请注意,在结构的最后一个元素中,我们传递了一个我们用exponents声明的全局数组的元素。因此,正如我们将在最终代码中看到的那样,我们将迭代整个数组,但是现在让我们保持简单。
argsStruct oneTask = { 0 , 1000 , n[i] };
argsStruct twoTasks1 = { 0 , 1000 / 2 , n[i] };
argsStruct twoTasks2 = { 1000 / 2 , 1000 , n[i] };
argsStruct fourTasks1 = { 0 , 1000 / 4 , n[i] };
argsStruct fourTasks2 = { 1000 / 4 , 1000 / 4 * 2, n[i]};
argsStruct fourTasks3 = { 1000 / 4 * 2, 1000 / 4 * 3, n[i]};
argsStruct fourTasks4 = { 1000 / 4 * 3 , 1000, n[i]};
现在,我们将使用单个任务进行测试。我们首先使用micros函数获取执行时间。然后,我们将使用 xTaskCreatePinnedToCore函数创建一个固定到其中一个核心的FreeRTOS任务。我们将选择核心1。
我们将作为参数传递oneTask结构变量的地址,该变量包含函数运行所需的参数。不要忘记演员无效*。
需要考虑的一个非常重要的事情是,我们还没有分析Arduino核心可能启动哪些任务,这可能会影响执行时间。因此,为了保证我们的任务将以更高的优先级执行,我们将为其分配值20.请记住,更高的数字意味着FreeRTOS调度程序的执行优先级更高。
启动任务后,我们将要求信号量的单位,确保设置功能将保持到新任务完成执行。最后,我们将打印执行时间。
Serial.println("");
Serial.println("------One task-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&oneTask, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
end = micros();
execTimeOneTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeOneTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
这几乎就是我们要对其他用例做的事情。唯一的区别是我们将启动更多任务,并且我们将尝试从信号量中获取更多单元(与为该用例启动的数量os任务一样多)。
检查下面的完整源代码,其中已包含运行代码的用例,包括两个任务(每个ESP32核心一个)和四个任务(每个ESP32核心两个)。此外,在设置功能结束时,它包括每次迭代的加速结果的打印。
请注意,Serial.println函数的额外参数指示浮点数的小数位数。
int n[10] = {2, 3, 4, 5, 10, 50, 100, 1000, 2000, 10000 };
int nArraySize = 10;
struct argsStruct {
int arrayStart;
int arrayEnd;
int n;
};
unsigned long start;
unsigned long end;
unsigned long execTimeOneTask, execTimeTwoTask, execTimeFourTask ;
SemaphoreHandle_t barrierSemaphore = xSemaphoreCreateCounting( 4, 0 );
int bigArray[10000], resultArray[10000];
void setup() {
Serial.begin(115200);
Serial.println();
randomSeed(analogRead(0));
for (int i = 0; i < 10000; i++) {
bigArray[i] = random(1, 10);
}
for (int i = 0; i < nArraySize; i++) {
Serial.println("#############################");
Serial.print("Starting test for n= ");
Serial.println(n[i]);
argsStruct oneTask = { 0 , 1000 , n[i] };
argsStruct twoTasks1 = { 0 , 1000 / 2 , n[i] };
argsStruct twoTasks2 = { 1000 / 2 , 1000 , n[i] };
argsStruct fourTasks1 = { 0 , 1000 / 4 , n[i] };
argsStruct fourTasks2 = { 1000 / 4 , 1000 / 4 * 2, n[i]};
argsStruct fourTasks3 = { 1000 / 4 * 2, 1000 / 4 * 3, n[i]};
argsStruct fourTasks4 = { 1000 / 4 * 3 , 1000, n[i]};
Serial.println("");
Serial.println("------One task-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&oneTask, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
end = micros();
execTimeOneTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeOneTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println("");
Serial.println("------Two tasks-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&twoTasks1, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"coreTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&twoTasks2, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
for (int i = 0; i < 2; i++) {
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
}
end = micros();
execTimeTwoTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeTwoTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println("");
Serial.println("------Four tasks-------");
start = micros();
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks1, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks2, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
0); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks3, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
xTaskCreatePinnedToCore(
powerTask, /* Function to implement the task */
"powerTask", /* Name of the task */
10000, /* Stack size in words */
(void*)&fourTasks4, /* Task input parameter */
20, /* Priority of the task */
NULL, /* Task handle. */
1); /* Core where the task should run */
for (int i = 0; i < 4; i++) {
xSemaphoreTake(barrierSemaphore, portMAX_DELAY);
}
end = micros();
execTimeFourTask = end - start;
Serial.print("Exec time: ");
Serial.println(execTimeFourTask);
Serial.print("Start: ");
Serial.println(start);
Serial.print("end: ");
Serial.println(end);
Serial.println();
Serial.println("------Results-------");
Serial.print("Speedup two tasks: ");
Serial.println((float) execTimeOneTask / execTimeTwoTask, 4 );
Serial.print("Speedup four tasks: ");
Serial.println((float)execTimeOneTask / execTimeFourTask, 4 );
Serial.print("Speedup four tasks vs two tasks: ");
Serial.println((float)execTimeTwoTask / execTimeFourTask, 4 );
Serial.println("#############################");
Serial.println();
}
}
void loop() {
}
void powerTask( void * parameters ) {
argsStruct myArgs = *((argsStruct*)parameters);
int product;
for (int i = myArgs.arrayStart; i < myArgs.arrayEnd; i++) {
product = 1;
for (int j = 0; j < myArgs.n; j++) {
product = product * bigArray[i];
}
resultArray[i]=product;
//resultArray [i] = pow(bigArray[i], myArgs.n);
}
xSemaphoreGive(barrierSemaphore);
vTaskDelete(NULL);
}
测试代码
要测试代码,只需使用Arduino IDE上传并打开串行监视器。您应该得到类似于图1的结果。当然,执行时间可能会有所不同。
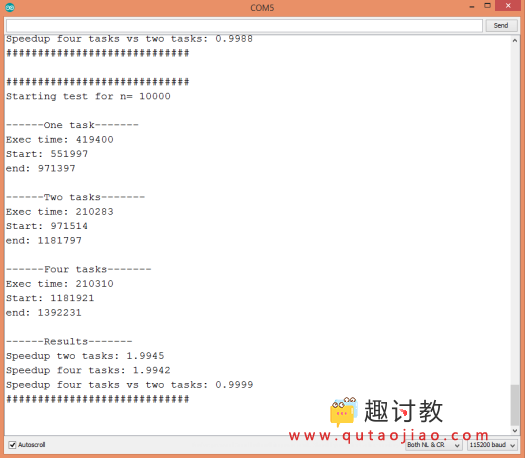
图1 – 加速测试程序的输出。
每个指数的结果如下表所示,见表1。
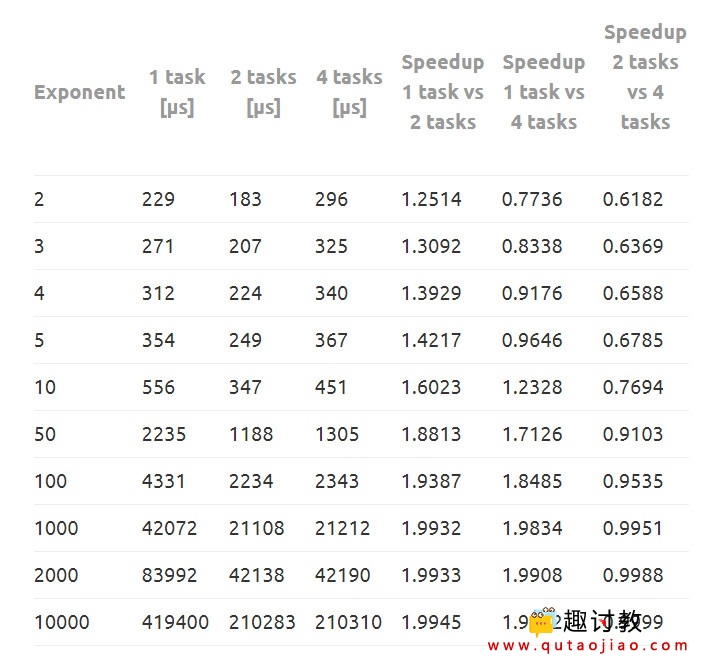
表1 – 代码中定义的指数的加速结果。
分析结果
为了理解结果,我们首先需要考虑到单个不能完全对整个程序进行整理。因此,总会有部分代码在单个核心中执行,例如启动任务或同步机制。
虽然我们没有这个用例,但是许多并行化算法也有一个部分,其中每个部分结果然后按顺序聚合(例如,如果我们有多个任务计算它们的数组部分的最大值,然后父任务计算所有部分结果之间的最大值)。
因此,无论我们做什么,我们理论上都无法实现等于核心数量的加速(例如,在搜索特定值并在找到时退出的算法中存在一些例外,但不要复杂化)。
因此,我们并行执行的计算与我们按顺序执行的部分相比,我们将获得更多的加速。这正是我们在结果中看到的。如果我们从指数2开始,我们从一个任务执行到两个任务的加速仅为 1.2514。
但是当我们增加指数值时,我们所做的内部循环的迭代次数越多,因此我们可以并行执行更多的计算。因此,随着我们增加指数,我们看到加速增加。例如,如果指数为1000,则我们的加速比为 1.9933。与之前相比,这是一个非常高的价值。
因此,这意味着顺序部分被稀释,对于大指数,并行化补偿。请注意,我们能够实现这些高值,因为该算法非常简单且易于并行化。此外,由于FreeRTOS处理优先级和任务执行上下文切换的方式,任务执行后没有太多开销。普通计算机往往在线程之间有更多的上下文切换,因此顺序开销更大。
请注意,我们没有使用pow函数来显示加速值的这种进展。pow函数使用浮点数,这意味着它的实现更加计算密集。因此,我们会在较低的指数上获得更好的加速,因为并行部分将比顺序部分更具相关性。您可以评论我们实现的算法并使用pow 函数来比较结果。
此外,重要的是要注意,启动比核心数更多的任务不会增加加速。实际上,它具有相反的效果。正如我们从结果中看到的那样,执行4个任务的速度总是低于执行2个任务的速度。实际上,对于低指数,执行具有4个任务的代码(即使它们分配在ESP32的两个核心中)实际上比在单个核心中执行任务更慢。
这是正常的,因为每个CPU只能在给定时间执行任务,因此启动比CPU更多的任务意味着更多的顺序时间来处理它们以及同步点上的更多开销。
不过,请注意,这并非总是黑白分明。如果任务有某种屈服点,他们将停止等待某些事情,那么拥有比核心更多的任务可能是有益的,以便使用免费的CPU周期。然而,在我们的例子中,CPU永远不会产生并且总是在执行,所以在启动超过2个任务方面,关于加速没有任何好处。
Amdahl定律
为了补充结果,我们将研究Amdahl定律。因此,我们将对我们使用的加速公式应用一些转换。最初的公式是加速等于顺序执行时间(我们称之为T)除以并行执行时间(我们称之为T Parallel)。
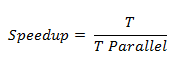
但是,正如我们所看到的,执行时间的一部分始终是顺序的,而另一部分可以并行化。让我们调用p我们可以并行运行的程序的一部分。由于它是一个分数,因此其值将介于0和1之间。
因此,我们可以将顺序执行时间T表示为可以并行执行的部分(p * T)加上不能(1-p)* T的部分。
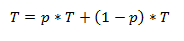
由于我们只能拆分机器核心之间的并行部分,因此T Parallel时间与上面的公式类似,只是并行部分显示除以我们可用的核心数。
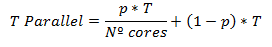
所以,我们的加速公式变为:
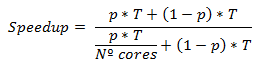
现在我们在T的功能上编写了加速,原始执行时间没有增强。所以,我们可以将每个项除以T:

因此,我们现在可以根据可以并行运行的部分和内核数量来编写加速。为了完成,让我们假设我们有无限量的内核可供执行(实际用例将是一个非常大的数字,但我们将以数学方式分析公式)。
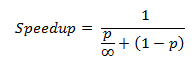
由于常数除以无穷大等于0,我们最终得到:
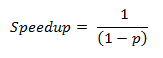
因此,虽然加速随着可用于并行化的资源数量(核心数量,在我们的例子中)而增加,但事实是可能的最大理论加速由非并行部分限制,我们无法优化。
这是一个有趣的结论,我们决定何时进行并行化。有时,算法可以很容易地并行化,并且我们有很大的加速,其他所需的努力并不能证明增益。
另外,要记住的其他重要事项是,并行化后最好的顺序算法并不总是最好的。因此,有时候,最好使用在顺序执行方面性能较差的算法,但最终要比并行化时最好的顺序算法好得多。
最后的笔记
通过本教程,我们确认可用于多核执行的功能运行良好,我们可以利用它们来获得性能优势。
最后一个理论部分的目标是显示并行化不是一个微不足道的问题,并且如果没有先前的分析,并且期望加速等于可用的核心数量,则无法直接进入并行方法。这种理性超出了ESP32的范围,一般适用于并行计算。
因此,对于那些将使用ESP32开始并行计算以提高性能的人来说,首先学习一些更理论的概念是一个良好的开端。
最后,请注意代码的目的是显示结果,因此可以进行许多优化,例如在循环中启动任务而不是重复代码或在函数中压缩算法。
此外,我们没有查看执行结果以确认输出数组是相同的,因为这不是我们的主要关注点。当然,从sequencial到parallel并行需要仔细执行代码并执行大量测试以确保结果相同。


